2. MEGMA Training & Transformation
2.1 Fitting MEGMA on metagenomic abundance data of all countries
2.2 Fitting MEGMA on metagenomic abundance data of one country only
MEGMA is an unsupervised learning method, and it can be trained by the metagnomic abundance data only (without label information), the 2D-microbiomeprints can be transformed by the trained megma object from the metagnomic abundance vectors.
Therefore, we can train the megma based on all of the metagnomic abundance data (megma_all) or metagnomic abundance data of only one country (for example, megma_usa for USA data). Fitting the megma object with different data can produce different 2D-microbiomeprints. Because different data controls the arrangement and placement of feature points (i.e., the microbes), the correlation distance matrix or similar matrix of the microbes can be different when calculated by different
data.
But in general, the correlation matrix calculated based on the whole data can be more robust and accurately (Because microbe-to-microbe correlation distances/similarities are measured with more samples), and consequently, the 2D-microbiomeprints can be more structured and patterned. In this example, we will show how to generate the 2D-microbiomeprints based on the whole data or one country data, and to see the differences of 2D-microbiomeprints.
[2]:
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
from aggmap import AggMap, AggMapNet
from aggmap import show, loadmap
import os
if not os.path.exists('./images'):
os.makedirs('./images')
2.1 Fitting MEGMA on metagenomic abundance data of all countries
Now, let’s try to use all of the unlabelled metagenomic abundance data to fit megma, and then to transform the 2D-microbiomeprints by the pre-fitted megma, the megma trained on all data is name as megma_all.
We can compare the 2D-microbiomeprints generated by the megma that fitted by all countries metagenomic abundance data and one country metagenomic abundance data.
2.1.1 Read and preprocess data for MEGMA
The metagenomic abundance data is logarithm-transformed, and to avoid the invalid logarithm transformation for zero values, a minimal value (1e-8) is added to all of the data. This operation is necessary because it can make sure that the pairwise correlation distance can be measured accurately.
[3]:
## dataset url
url = 'https://raw.githubusercontent.com/shenwanxiang/bidd-aggmap/master/docs/source/_example_MEGMA/dataset/'
countries = ['CHN', 'AUS', 'DEU', 'FRA', 'USA']
minv = 1e-8 #minimal value for log-transform
## Concate data of all countries
all_dfx = []
for country in countries:
dfx_vector = pd.read_csv(url + '%s_dfx.csv' % country, index_col='Sample_ID')
all_dfx.append(dfx_vector)
dfx_all = pd.concat(all_dfx, axis=0)
dfx_all = np.log(dfx_all + minv)
print('The number of samples to pre-fit: %s, the number of feature points: %s. \n' % dfx_all.shape)
The number of samples to pre-fit: 575, the number of feature points: 849.
[4]:
dfx_all[dfx_all.columns[:4]].head(8)
[4]:
| Clostridium saccharogumia [ref_mOTU_v2_0473] | Clostridium innocuum [ref_mOTU_v2_0643] | Clostridium sp. KLE 1755 [ref_mOTU_v2_0860] | Clostridium scindens [ref_mOTU_v2_0883] | |
|---|---|---|---|---|
| Sample_ID | ||||
| ERR1018185 | -18.420681 | -9.271705 | -9.271705 | -8.578611 |
| ERR1018186 | -18.420681 | -8.889649 | -7.097950 | -8.196538 |
| ERR1018187 | -18.420681 | -9.300529 | -8.607436 | -8.607436 |
| ERR1018188 | -18.420681 | -8.072227 | -9.170776 | -8.072227 |
| ERR1018189 | -18.420681 | -18.420681 | -18.420681 | -18.420681 |
| ERR1018190 | -18.420681 | -8.601296 | -7.502720 | -8.601296 |
| ERR1018191 | -18.420681 | -9.211839 | -18.420681 | -5.383296 |
| ERR1018192 | -18.420681 | -5.575946 | -8.943168 | -18.420681 |
2.1.2 MEGMA initialization, fitting and dump
In the initialization stage, MEGMA supports a varity of metric to measure the distances between the microbes. The default metric is the correlation distance. Importantly, MEGMA also supports to input a pre-difined distance matrix ( the info_distance parameter) for of microbes.
In the fitting stage, MEGMA default uses the UMAP (the emb_method parameter) method to perform the embedding of the microbes, the parameter cluster_channels is for the grouping of the microbes, it uses the hierarchical clustering algrothm to generate the subgroups of the microbes. Importantly, MEGMA also supports to input a pre-difined (or customized) microbial subgroup list (i.e., the feature_group_list parameter, it can be used to customize the group of the microbes). More
information about Embedding & Grouping can be see here.
The important hyperparameters for microbial embedding are var_thr, random_state, n_neighbors, n_epochs. These parameters can control how megma to arrange the microbes in the 2D. var_thr may affect the model performance most. The parameter var_thr can be used to filter out some microbes in very low variances, under the low sample size case (the unlabeled data to fit MEGMA), the variances of same feature points can be very low. Please be noted that the parameter
var_thr is a feature selection parameter and is quite important for low-sample size cases. In practical, var_thr can be optimized by the performance the model. In general, higher var_thr value can help to generate a more structured feature maps, and therefore the model performance can be improved. If the variance of the feature points is very low, the resulting feature maps will be more randomly arranged. This is because the correlation distances between feature points with low
variance cannot be measured very accurately. Consequently, the Fmap looks like a random arrangement. However, the threshold var_thr that is too high will lead to a decrease in the number of retained features, which may also lead to the deterioration of model performance. Therefore, we recommended that the var_thr is a hyperparameters and shold be optimized by the performance the model. the var_thr should be at least greater than 0. More information on the hyperparameters is avaliable
here.
The object megma can be dumped in your disk and then loaded next time by loadmap. Basically, the megma object is same as a trained model, once it is fitted by the unlabelled data, it can be used to transform an 1D vector into 3D tensor, i.e., the multichannel Fmaps.
[5]:
## parameters in MEGMA
metric = 'correlation' #distance metric
emb_method = 'umap' #embedding method
cluster_channels = 5 #channel number
## Fitting on all of the data
megma_all = AggMap(dfx_all, metric = metric, by_scipy = True,)
megma_all = megma_all.fit(emb_method = emb_method,
cluster_channels = cluster_channels,
feature_group_list = [],
var_thr = 0,
verbose = 0)
## save megma
megma_all.save('./megma/megma.all')
#delete megma from memory
del megma_all
2022-08-23 12:27:14,465 - INFO - [bidd-aggmap] - Calculating distance ...
100%|###############################################################################| 849/849 [00:00<00:00, 5370.94it/s]
2022-08-23 12:27:14,694 - INFO - [bidd-aggmap] - applying hierarchical clustering to obtain group information ...
2022-08-23 12:27:17,007 - INFO - [bidd-aggmap] - Applying grid assignment of feature points, this may take several minutes(1~30 min)
2022-08-23 12:27:18,007 - INFO - [bidd-aggmap] - Finished
2.1.3 MEGMA loading and 2D-microbiomeprints transformation
Now, we have deleted the megma_all in our memory, but we can reload it by loadmap.
Once we have fitted our megma, we are able to use it to transform the abundance vectors. In the transformation stage, metagenomic abundance vector data can be scaled by scale_method. The standard method is for the z-score standard scaling, and the megma_all.batch_transform method can transform a set of 1D vectors to 3D tensors (-1, w, h, c), while the megma_all.transform method is to transform one 1D vector to one 3D tensor (1, w, h, c).
[6]:
#reload megma from disk
megma_all = loadmap('./megma/megma.all')
scale_method = 'standard'#scale method
country = 'USA' # transform the 2D-microbiomeprints for one country
dfx_vector = pd.read_csv(url + '%s_dfx.csv' % country, index_col='Sample_ID')
dfx_vector = np.log(dfx_vector + minv)
X_tensor = megma_all.batch_transform(dfx_vector.values, scale_method = scale_method)
X_tensor.shape
100%|#################################################################################| 104/104 [00:01<00:00, 60.50it/s]
[6]:
(104, 30, 29, 5)
[7]:
dfy = pd.read_csv(url + '%s_dfy.csv' % country, index_col='Sample_ID')
idx = dfy.reset_index().groupby(['Country', 'Group']).apply(lambda x:x.index.tolist())
idx
[7]:
Country Group
USA CRC [2, 3, 4, 5, 6, 9, 12, 14, 16, 19, 28, 29, 30,...
CTR [0, 1, 7, 8, 10, 11, 13, 15, 17, 18, 20, 21, 2...
dtype: object
2.1.4 MEGMA 2D-microbiomeprints visulization
The trained megma object has attributes of plot_grid, plot_scatter, plot_tree for data visulization. The plot_grid is to plot a regular grid, and in this grid, each microbe has an optimized postion, its neighbors are abundance-correlated microbes. The plot_scatter is to plot the 2D embedding results of the microbes, the plot_tree is to plot the clustering tree of the microbes.
[8]:
megma_all.plot_grid(htmlpath='./images', htmlname = 'megma_all')
2022-08-23 12:27:19,979 - INFO - [bidd-aggmap] - generate file: ./images/megma_all_feature points_849_correlation_umap_mp
2022-08-23 12:27:19,987 - INFO - [bidd-aggmap] - save html file to ./images/megma_all_feature points_849_correlation_umap_mp
[8]:
[9]:
fig = megma_all.plot_tree(add_leaf_labels=False, leaf_font_size = 1)
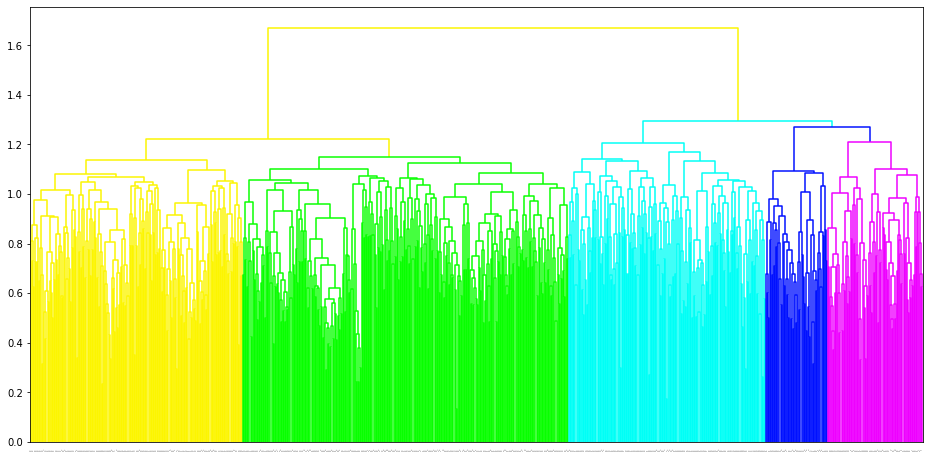
2.1.5 Well-trained MEGMA to transform the abundance data of each country
Next, let’s to show the transformed feature maps (aka the 2D-microbiomeprints or 3D tensor). the well-trained megma_all object is able to transform the data of the rest of countries.
[10]:
def plot(X, megma, rows, fname = './Country1_fmp.png'):
n = 5
fontsize = 40
fig, axes = plt.subplots(nrows=2, ncols=n, figsize=(22,9), sharex = True, sharey = True)
row_names = [', '.join(i) for i in rows]
for row, row_ax in zip(rows, axes):
pidx = idx.loc[row][:n]
for pid, ax in zip(pidx, row_ax):
cid = row[0]
pid_name = '%s-%s' % (cid, pid)
x = X[pid]
color_list = pd.Series(megma.colormaps).sort_index().iloc[1:].tolist()
color_list.append('#000000')
show.imshow(x, ax = ax, mode = 'dark', color_list= color_list, x_max=3, vmin=-0.5, vmax=0.9)
ax.set_title(pid_name, fontsize = fontsize)
for ax, row in zip(axes[:,0], row_names):
ax.set_ylabel(row.split(',')[1], fontsize = fontsize)
fig.tight_layout()
fig.savefig(fname, bbox_inches='tight', dpi=400)
[11]:
for country in countries:
dfx_vector = pd.read_csv(url + '%s_dfx.csv' % country, index_col='Sample_ID')
dfx_vector = np.log(dfx_vector + minv)
X_tensor = megma_all.batch_transform(dfx_vector.values, scale_method = scale_method)
print('Trained MEGMA has transformed 3D tensor for %s data' % country)
dfy = pd.read_csv(url + '%s_dfy.csv' % country, index_col='Sample_ID')
idx = dfy.reset_index().groupby(['Country', 'Group']).apply(lambda x:x.index.tolist())
rows = idx.index.tolist()
rows = rows[:2]
plot(X_tensor, megma_all, rows, fname = './images/fmp_megma_all_%s.png' % country)
100%|###############################################################################| 128/128 [00:00<00:00, 2379.22it/s]
Trained MEGMA has transformed 3D tensor for CHN data
100%|###############################################################################| 109/109 [00:00<00:00, 2282.86it/s]
Trained MEGMA has transformed 3D tensor for AUS data
100%|###############################################################################| 120/120 [00:00<00:00, 2224.45it/s]
Trained MEGMA has transformed 3D tensor for DEU data
100%|###############################################################################| 114/114 [00:00<00:00, 2433.32it/s]
Trained MEGMA has transformed 3D tensor for FRA data
100%|###############################################################################| 104/104 [00:00<00:00, 2187.51it/s]
Trained MEGMA has transformed 3D tensor for USA data





2.2 Fitting MEGMA on metagenomic abundance data of one country only
In this section, we will fit the megma object on etagenomic abundance data of one country only (such as the USA data, we will name the fitted megma object as megma_usa in this example), later we can transform the data from the rest of the country by the trained country-specific MEGMA.
2.2.1 Read and preprocess data for MEGMA
We use the same data preprocessing method as above, and read one country metagenomic abundance data for fitting of MEGMA
[12]:
## dataset
country = 'USA' # 'USA', 'FRA', 'AUS', 'DEU', 'CHN'
url = 'https://raw.githubusercontent.com/shenwanxiang/bidd-aggmap/master/docs/source/_example_MEGMA/dataset/'
dfx = pd.read_csv(url + '%s_dfx.csv' % country, index_col='Sample_ID')
dfy = pd.read_csv(url + '%s_dfy.csv' % country, index_col='Sample_ID')
dfx = np.log(dfx + minv)
2.2.2 MEGMA initialization & fitting
As we have discussed above, the parameter var_thr is a feature selection parameter and is quite important for low-sample size cases. Since we only use one country’s metagenomic abundance data to fit megma, the var_thr should be adjusted so that we can remove those microbes that are in a quite low variance.
If the variance of a feature point (aka, a microbe) is very low, the resulting feature maps will be more randomly arranged. This is because the correlation distances between feature points with low variance cannot be measured very accurately. Consequently, the Fmap looks like a random arrangement. However, the threshold var_thr that is too high will lead to a decrease in the number of retained features, which may also lead to the deterioration of model performance. Therefore, we recommended
that the var_thr is a hyperparameters and shold be optimized by the performance the model.
[13]:
megma_usa = AggMap(dfx, by_scipy=True, info_distance = None)
megma_usa = megma_usa.fit(var_thr = 3.,
#can be optimized by each megma based on their model performance, such as 1, 2, 4, 8, 10, ..
verbose = 0)
2022-08-23 12:27:38,485 - INFO - [bidd-aggmap] - Calculating distance ...
100%|###############################################################################| 849/849 [00:00<00:00, 5552.14it/s]
2022-08-23 12:27:38,655 - INFO - [bidd-aggmap] - applying hierarchical clustering to obtain group information ...
2022-08-23 12:27:39,203 - INFO - [bidd-aggmap] - Applying grid assignment of feature points, this may take several minutes(1~30 min)
2022-08-23 12:27:39,420 - INFO - [bidd-aggmap] - Finished
2.2.3 MEGMA 2D-microbiomeprints transformation
[14]:
X = megma_usa.batch_transform(dfx.values, scale_method = scale_method)
X.shape
100%|###############################################################################| 104/104 [00:00<00:00, 2291.07it/s]
[14]:
(104, 28, 27, 5)
2.2.4 MEGMA Fmaps visulization
[15]:
megma_usa.plot_grid(htmlpath='./images', htmlname = 'megma_%s' % country)
2022-08-23 12:27:39,545 - INFO - [bidd-aggmap] - generate file: ./images/megma_USA_feature points_752_correlation_umap_mp
2022-08-23 12:27:39,551 - INFO - [bidd-aggmap] - save html file to ./images/megma_USA_feature points_752_correlation_umap_mp
[15]:
[16]:
fig = megma_usa.plot_tree(add_leaf_labels = False, leaf_font_size = 1)
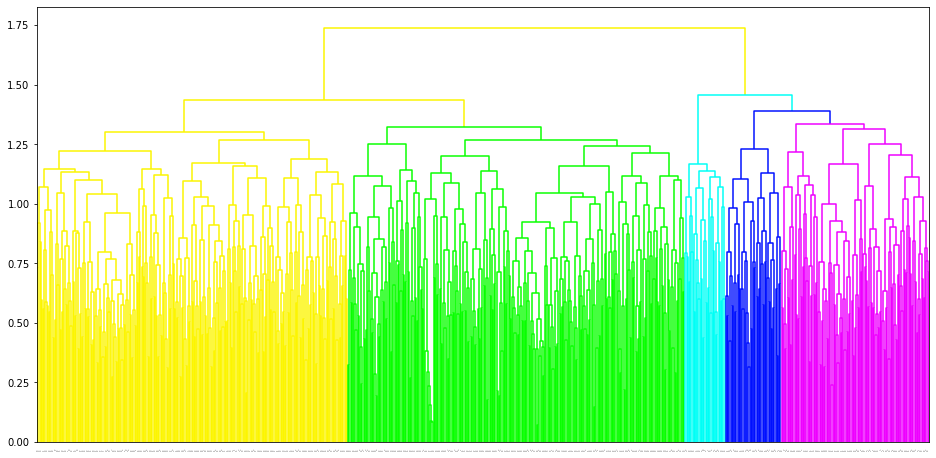
[17]:
idx = dfy.reset_index().groupby(['Country', 'Group']).apply(lambda x:x.index.tolist())
idx
[17]:
Country Group
USA CRC [2, 3, 4, 5, 6, 9, 12, 14, 16, 19, 28, 29, 30,...
CTR [0, 1, 7, 8, 10, 11, 13, 15, 17, 18, 20, 21, 2...
dtype: object
[18]:
sns.palplot(megma_usa.group_color_dict.values())

[19]:
rows = idx.index.tolist()
rows = rows[:2]
plot(X, megma_usa, rows, fname = './images/fmp_megma_usa_%s.png' % country)

2.2.5 Transform the abandance data of the rest countries by country-specific MEGMA
We have trained the MEGMA based on one country data, of course it now can transform the metagenomic vector data of this country, but it can also be used to transform the metagenomic vector data of the rest of the countries.
[20]:
for country in countries:
dfx_vector = pd.read_csv(url + '%s_dfx.csv' % country, index_col='Sample_ID')
dfx_vector = np.log(dfx_vector + minv)
X_tensor = megma_usa.batch_transform(dfx_vector.values, scale_method = scale_method)
print('Trained MEGMA has transformed 3D tensor for %s data' % country)
dfy = pd.read_csv(url + '%s_dfy.csv' % country, index_col='Sample_ID')
idx = dfy.reset_index().groupby(['Country', 'Group']).apply(lambda x:x.index.tolist())
rows = idx.index.tolist()
rows = rows[:2]
plot(X_tensor, megma_usa, rows, fname = './images/fmp_megma_usa_%s.png' % country)
100%|###############################################################################| 128/128 [00:00<00:00, 1524.35it/s]
Trained MEGMA has transformed 3D tensor for CHN data
100%|###############################################################################| 109/109 [00:00<00:00, 2484.37it/s]
Trained MEGMA has transformed 3D tensor for AUS data
100%|###############################################################################| 120/120 [00:00<00:00, 2370.25it/s]
Trained MEGMA has transformed 3D tensor for DEU data
100%|###############################################################################| 114/114 [00:00<00:00, 2600.77it/s]
Trained MEGMA has transformed 3D tensor for FRA data
100%|###############################################################################| 104/104 [00:00<00:00, 2368.87it/s]
Trained MEGMA has transformed 3D tensor for USA data
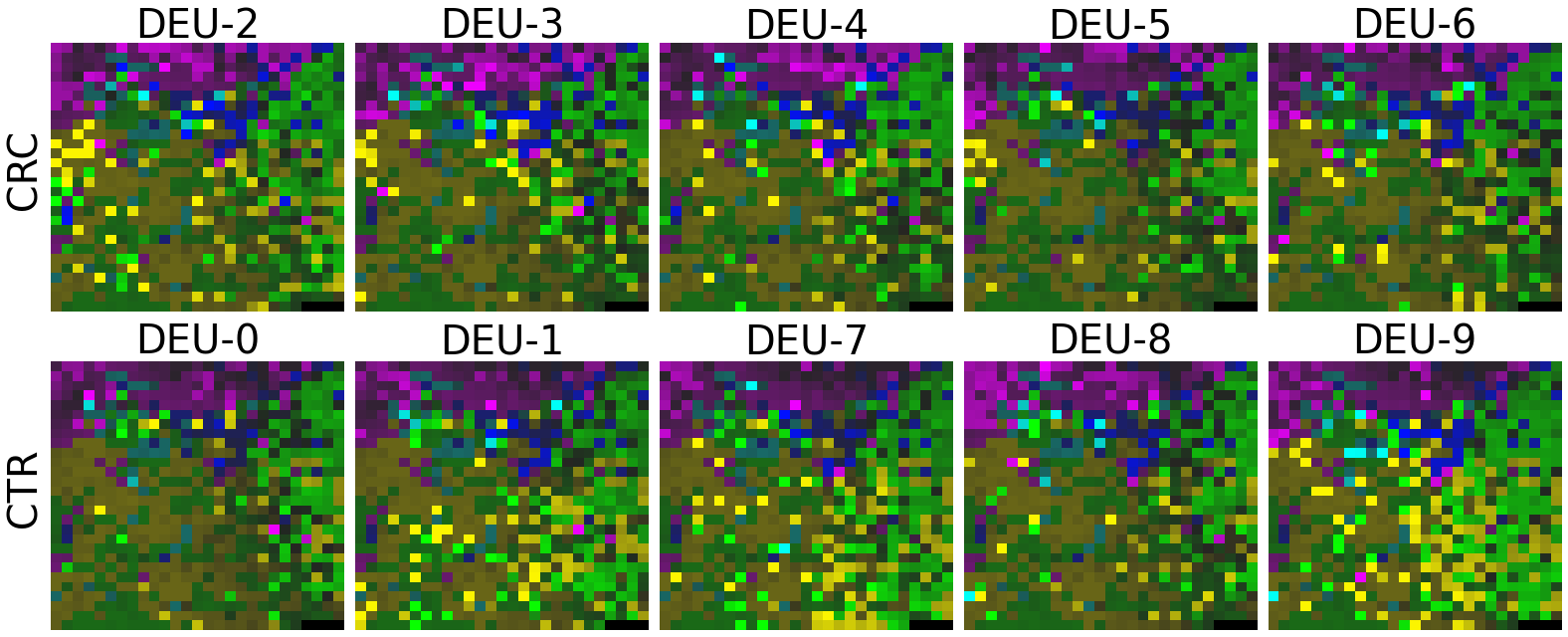
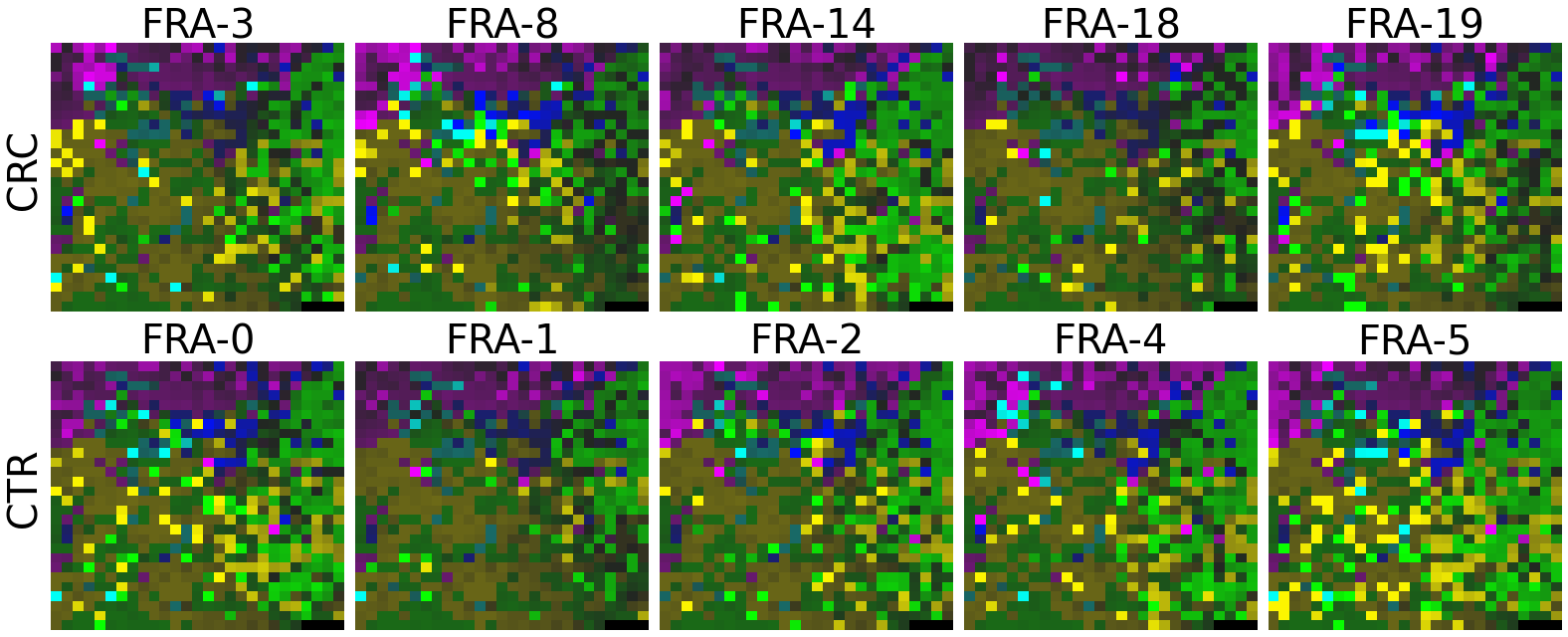

2.2.6 Fitting country-specific megma for all countries
[21]:
megmas = []
for country in countries:
dfx_vector = pd.read_csv(url + '%s_dfx.csv' % country, index_col='Sample_ID')
dfx_vector = np.log(dfx_vector + minv)
megma = AggMap(dfx_vector, by_scipy=True)
megma = megma.fit(#can be optimized by each megma based on their model performance, such as 1, 2, 4, 8, 10, ..
var_thr = 3.,
verbose = 0)
print(country, megma.fmap_shape)
megma.save('./megma/megma.%s' % country)
megmas.append(megma)
##### plot the Fmaps
# X = megma.batch_transform(dfx_vector.values, scale_method = scale_method)
# dfy = pd.read_csv(url + '%s_dfy.csv' % country, index_col='Sample_ID')
# idx = dfy.reset_index().groupby(['Country', 'Group']).apply(lambda x:x.index.tolist())
# rows = idx.index.tolist()
# rows = rows[:2]
# plot(X, megma, rows, fname = './images/fmp_megma_%s_%s.png' % (country, country))
2022-08-23 12:28:00,153 - INFO - [bidd-aggmap] - Calculating distance ...
100%|###############################################################################| 849/849 [00:00<00:00, 5608.91it/s]
2022-08-23 12:28:00,322 - INFO - [bidd-aggmap] - applying hierarchical clustering to obtain group information ...
2022-08-23 12:28:00,773 - INFO - [bidd-aggmap] - Applying grid assignment of feature points, this may take several minutes(1~30 min)
2022-08-23 12:28:01,090 - INFO - [bidd-aggmap] - Finished
CHN (26, 25)
2022-08-23 12:28:01,232 - INFO - [bidd-aggmap] - Calculating distance ...
100%|###############################################################################| 849/849 [00:00<00:00, 5700.32it/s]
2022-08-23 12:28:01,396 - INFO - [bidd-aggmap] - applying hierarchical clustering to obtain group information ...
2022-08-23 12:28:01,915 - INFO - [bidd-aggmap] - Applying grid assignment of feature points, this may take several minutes(1~30 min)
2022-08-23 12:28:02,245 - INFO - [bidd-aggmap] - Finished
AUS (28, 27)
2022-08-23 12:28:02,393 - INFO - [bidd-aggmap] - Calculating distance ...
100%|###############################################################################| 849/849 [00:00<00:00, 5653.09it/s]
2022-08-23 12:28:02,559 - INFO - [bidd-aggmap] - applying hierarchical clustering to obtain group information ...
2022-08-23 12:28:03,088 - INFO - [bidd-aggmap] - Applying grid assignment of feature points, this may take several minutes(1~30 min)
2022-08-23 12:28:03,395 - INFO - [bidd-aggmap] - Finished
DEU (28, 27)
2022-08-23 12:28:03,543 - INFO - [bidd-aggmap] - Calculating distance ...
100%|###############################################################################| 849/849 [00:00<00:00, 5692.89it/s]
2022-08-23 12:28:03,707 - INFO - [bidd-aggmap] - applying hierarchical clustering to obtain group information ...
2022-08-23 12:28:04,259 - INFO - [bidd-aggmap] - Applying grid assignment of feature points, this may take several minutes(1~30 min)
2022-08-23 12:28:04,840 - INFO - [bidd-aggmap] - Finished
FRA (28, 28)
2022-08-23 12:28:05,275 - INFO - [bidd-aggmap] - Calculating distance ...
100%|###############################################################################| 849/849 [00:00<00:00, 5661.03it/s]
2022-08-23 12:28:05,439 - INFO - [bidd-aggmap] - applying hierarchical clustering to obtain group information ...
2022-08-23 12:28:05,977 - INFO - [bidd-aggmap] - Applying grid assignment of feature points, this may take several minutes(1~30 min)
2022-08-23 12:28:06,198 - INFO - [bidd-aggmap] - Finished
USA (28, 27)
2.3 Discussions & conclusions on MEGMA 2D-microbiomeprints
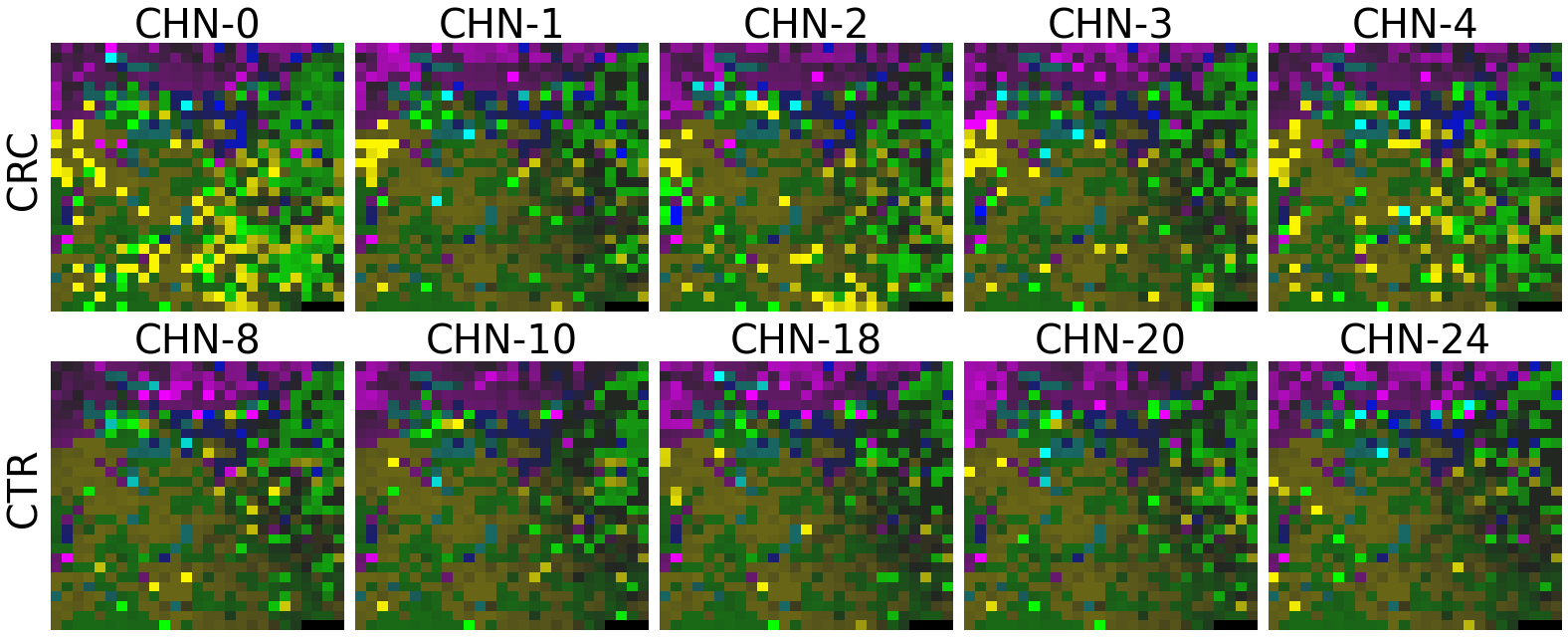
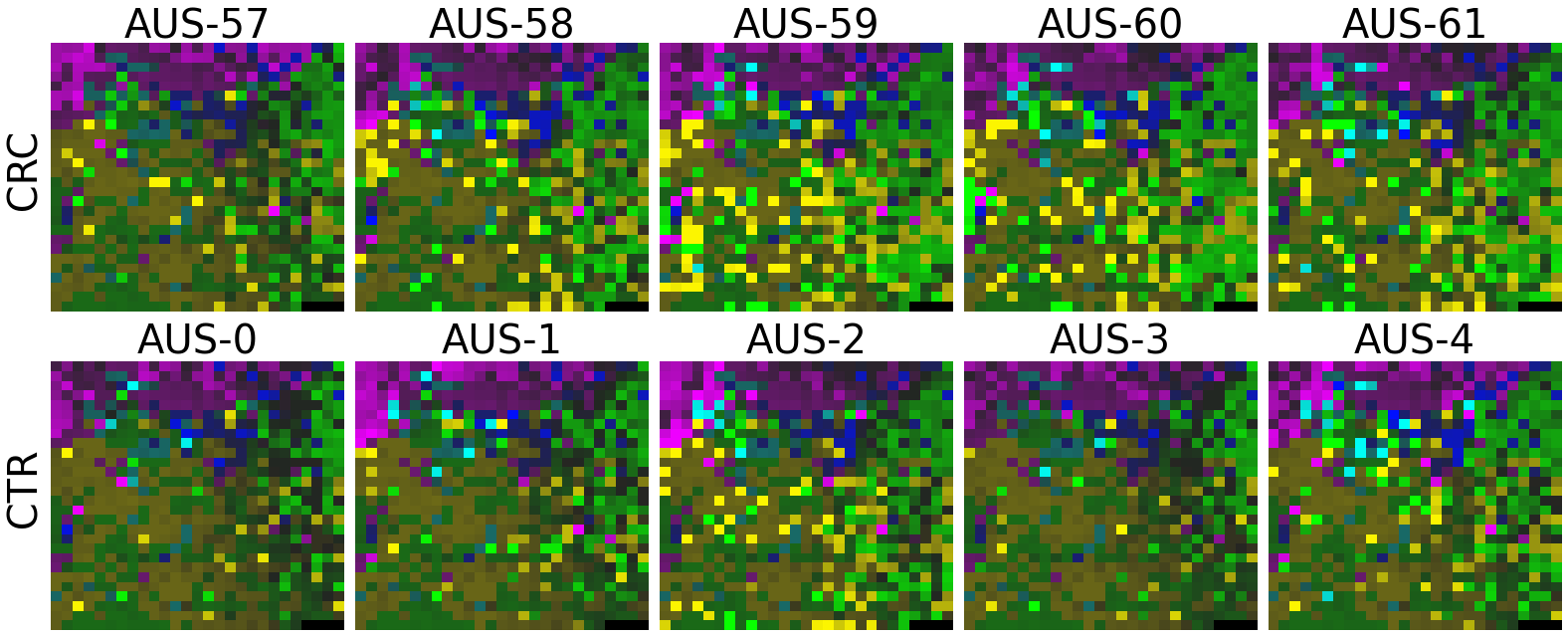
Now, let’s use our naked eyes (label the important zone manually) to find the distinct area between the CRCs and CTRs in the generated 2D-microbiomeprints by the megma_all and megma_usa objects, respectively.
We can indentify the important zone of megma_all generated 2D-microbiomeprints easily, it is located in the top left corner of the feature maps (Fig.1, red boxes). However, the important zone for megma_usa generated 2D-microbiomeprints is different, which is located in a different region of the feature maps (Fig.2, red boxes). This is because when different datasets are used to fit megma object, the final arrangement of microbes is different due to the inconsistent
correlation distance between microbes determined by the datasets. Nonetheless, important microbes always cluster together to form hotspots.
Furthermore, the microbes in the red-box zone of megma_usa Fmaps are same as the microbes in the red-box zone of megma_all Fmaps (You can find out the microbial names in grid plots of megma_usa and megma_all). In subsequent analyses, we will identify these important microbes based on interpretable deep learning methods, to find out whether the microbes in different hot zones generated by the two methods are consistent or not.
Except for that, we can draw anther important conlusion, that is, the feature maps generated by megma_usa for USA data is much more ordered and structured than the data in the rest of the countries, this is because the megma_usa is only trained on the USA data. On the feature maps generated by megma_all, we can see that the feature maps of all countries are quite ordered and structured. Therefore, in practical usage, we’d like to recommend to fit on larger samples, because
the intrinsic relationship between feature points can be better exposed by higher-sample data. Unsupervised megma operates in separate fitting and transformation stages for enabling transfer learning. The fitting operation can be trained on higher-sample unlabeled data and subsequently used for transforming low-sample unlabeled data. megma can also be dumped into local disk and reloaded next time for re-fitting or transformation.
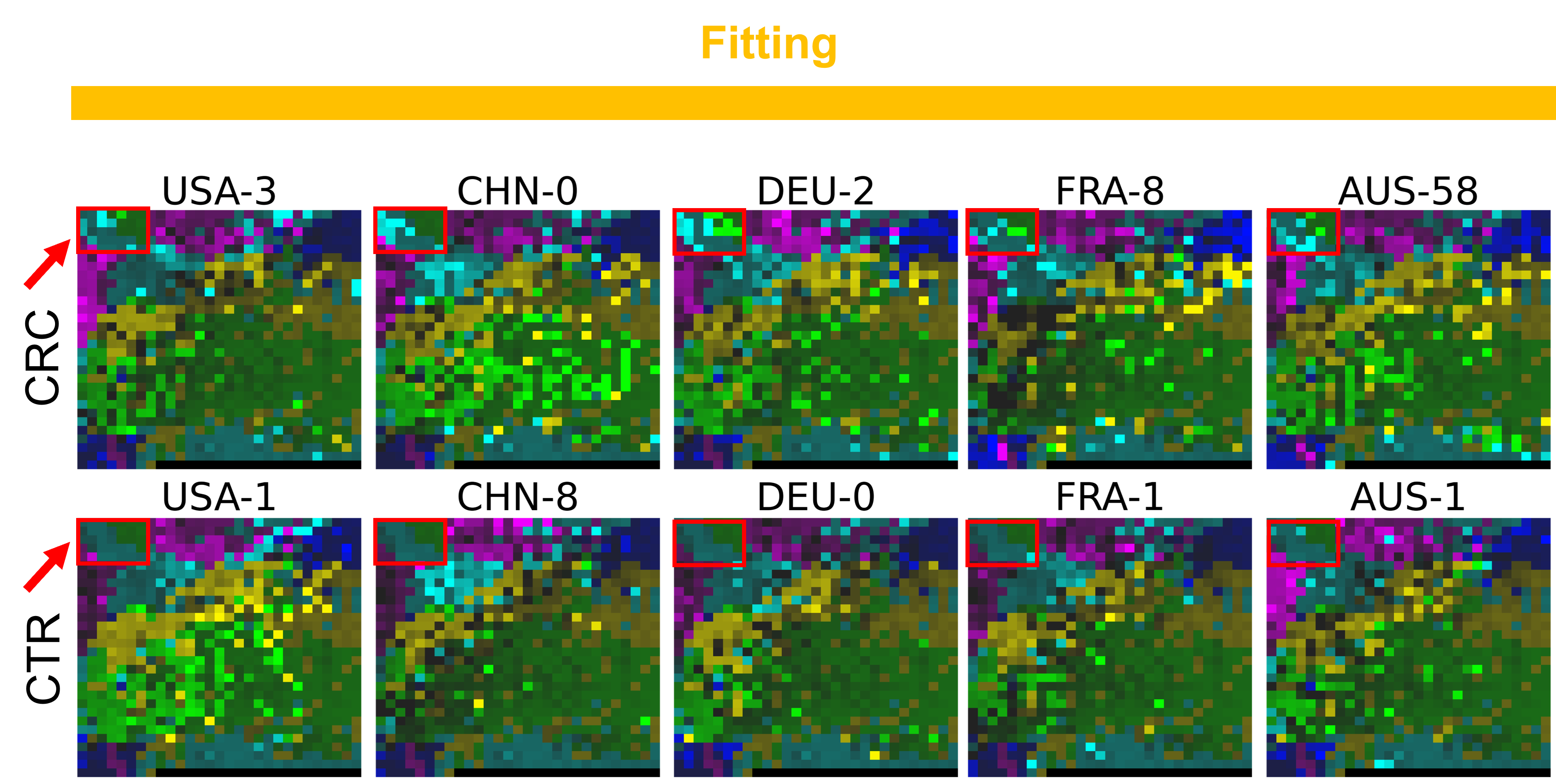
Fig.1 the megma_all generated 2D-microbiomeprints for the five countries, the important zone identified by naked eye (distinct zone of CRCs from healthy controls) is highlight by the red box.
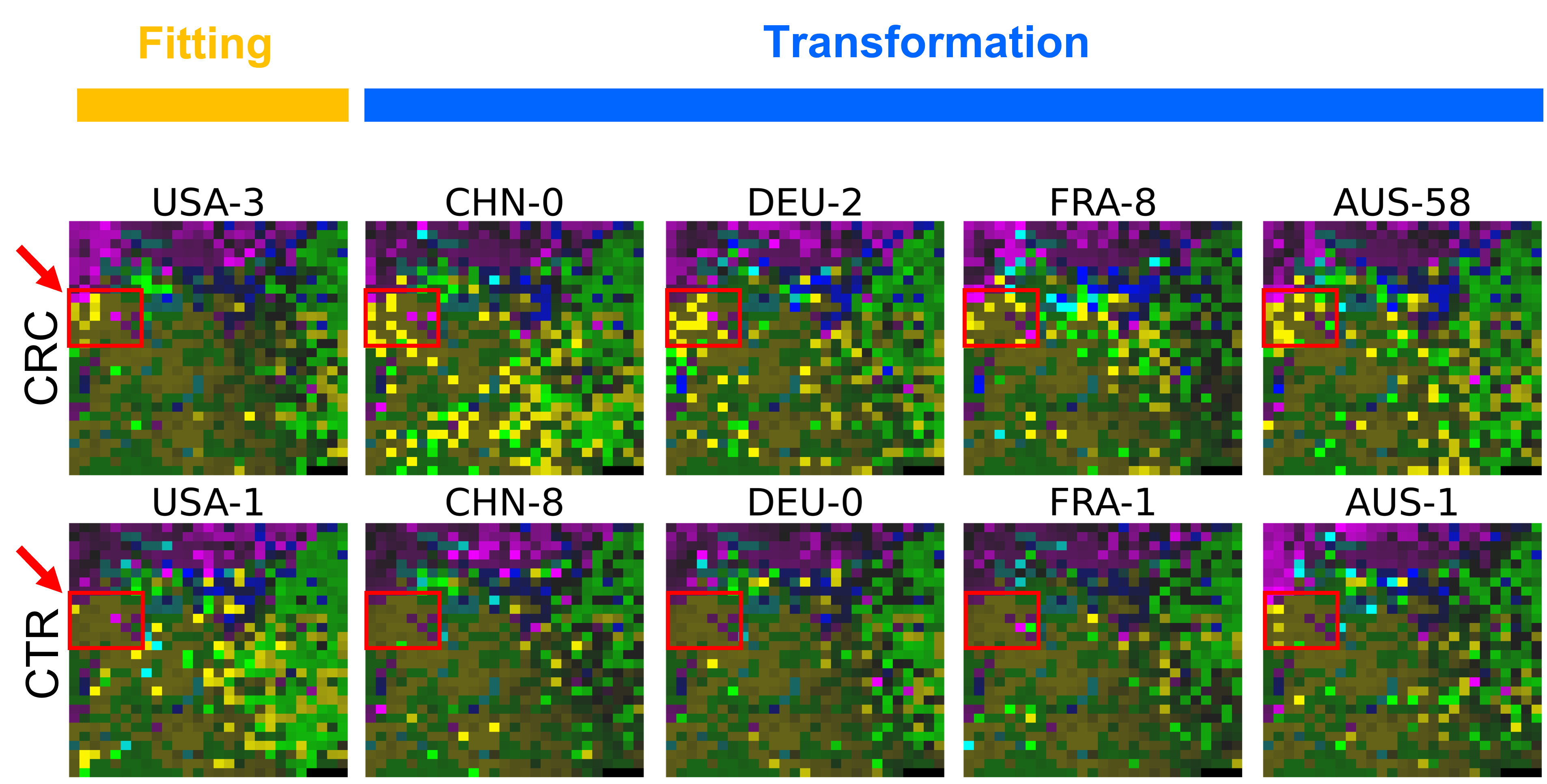
Fig.2 the megma_usa generated 2D-microbiomeprints for the five countries, the important zone identified by naked eye (distinct zone of CRCs from healthy controls) is highlight by the red box.